What is Seed Coder?
Seed Coder is a family of open-source code large language models (LLMs) developed by ByteDance Seed. It's designed specifically for coding tasks and comes in three variants: base, instruct, and reasoning, all at 8B scale.
What are the different variants and their purposes?
The model comes in three specialized variants: Base (general coding capabilities), Instruct (optimized for following specific coding instructions), and Reasoning (focused on complex problem-solving and algorithms). Each variant is optimized for different coding needs.
How does Seed Coder perform compared to other models?
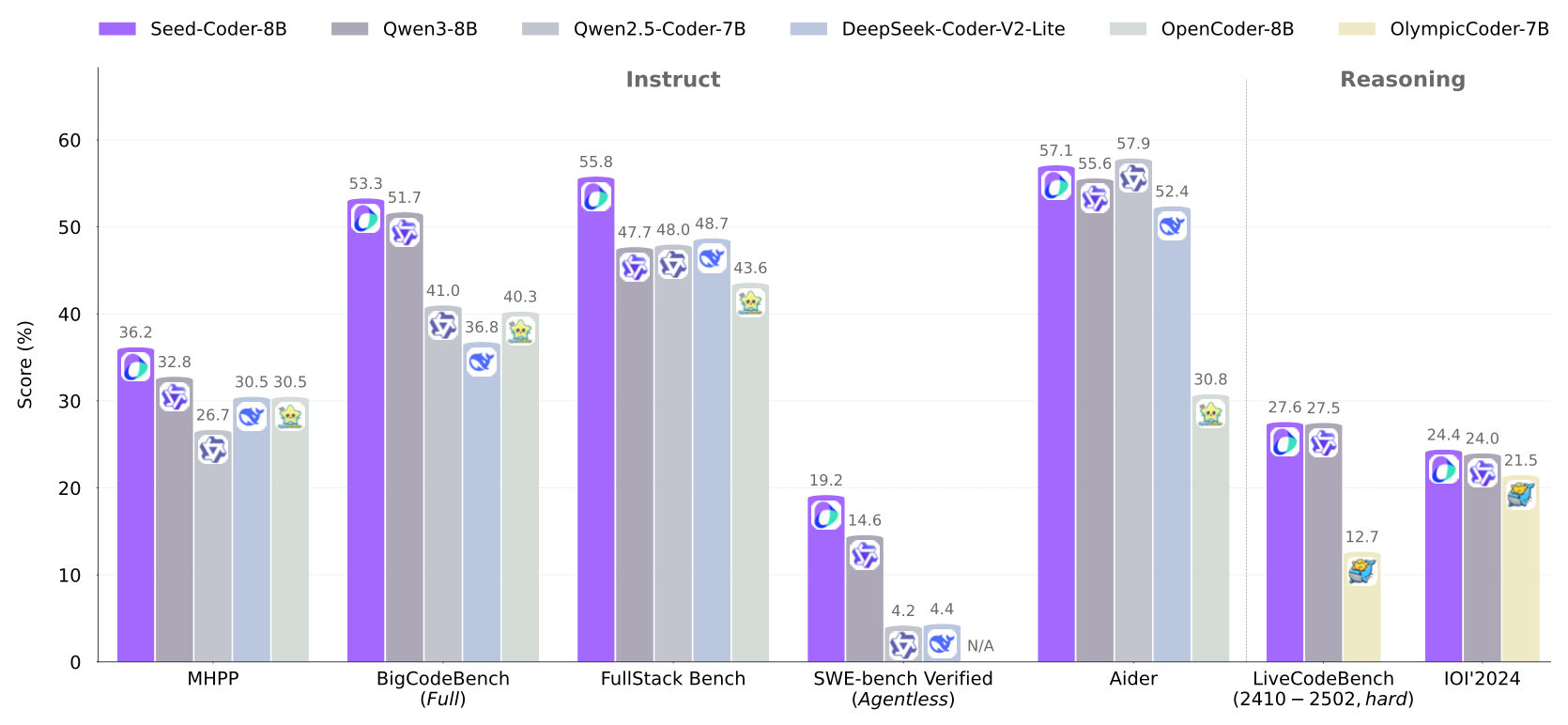
Seed Coder shows strong performance among open-source models of similar size. It excels in benchmarks like SWE-bench Verified and Multi-SWE-bench mini, and even outperforms some larger models in Agentless workflows. The Reasoning variant has shown impressive results in competitive programming tasks.
What makes Seed Coder unique?
Seed Coder stands out for its model-centric approach to data curation, complete transparency in its data pipeline, and strong performance in coding tasks. It uses LLMs for data filtering, reducing manual effort while maintaining high quality.
How can I access and use Seed Coder?
Seed Coder is open-source and available on both GitHub and Hugging Face. You can download the models, access the technical documentation, and integrate them into your development workflow. The project includes comprehensive documentation for implementation.
What are the system requirements?
As an 8B parameter model, Seed Coder requires appropriate computational resources. The exact requirements depend on your use case, but it's designed to balance performance and efficiency, making it suitable for various deployment scenarios.
How is the model trained and maintained?
Seed Coder uses a model-centric approach for data curation, leveraging LLMs to process data from GitHub, commits, and code-related web sources. The development process is transparent, with detailed documentation available in the technical report.
What are the potential applications?
Seed Coder can be used for various coding tasks including code generation, debugging, and educational purposes. Its different variants make it suitable for both basic coding assistance and complex algorithmic problem-solving.
Is there community support available?
Yes, Seed Coder has an active open-source community. You can find support through GitHub discussions, community forums, and the project's documentation. The community actively contributes to improvements and adaptations of the model.
What's the future roadmap for Seed Coder?
Seed Coder aims to continue advancing code intelligence through community contributions and updates. The project focuses on improving performance, expanding capabilities, and fostering broader applications in the coding community.